
The first time you learn about formal logic, you may experience a bout of cynicism. For many, formal logic is typical of the impractical rigor of academia and its obsession with formalisms; an exercise in pure semantics- surely, simply messing around with statements about what is, can never tell us what it is that we can do-. I believe this attitude contributes to the now-esoteric state of logic programming as a whole.
When I first learned logic programming, I felt it was stale, pointless, and dull - but now I understand that it is as much a paradigm shift as going from imperative to functional. It’s not intuitive, but I began to realise that logical and relational languages allow me to express ideas in a concise declarative manner, and that I can take the knowledge and insights I gained from my studies back to the functional world to power my abstractions.
I want to demonstrate the (at least pedagogical) value of logical and relational programming in this article.
Prolog is one of the oldest and most well-known logic languages (and the progenitor of Erlang, and that story is fascinating in its own right). The basic unit of abstraction in Prolog is a Horn Clause. Horn clauses consist of two parts:
- The ‘head’ (a goal clause), which is constituted by the name of the predicate we are defining and its arity- the number of arguments the predicate takes
- The ‘body’, which can be considered to be ‘conditionals’- if all the predicates in the body are true, then the head is true (equivalent to logical ‘and’).
Let’s consider a couple of examples.
parent(John, Jill).
parent(John, Jack).Above we assert that the predicate John is the parent of Jill, and that John is also the parent of Jack. There are no conditions under which it is true- hence it is true by default, and this is what we call a ‘fact’.
A Prolog program begins with a set of ‘facts’ are that known to be true. When we define a predicate, Prolog adds the fact to its environment, to be used later.
We can also define multiple definitions for the predicate, and this is equivalent to a logical ‘or’- parent is true if the first argument is John and the second argument is Jill, OR if the first argument is John and the second is Jack.
Now let’s start to define what it means to be an ‘ancestor’.
ancestor(X, Y) :- parent(X, Y).This statement means that to be an ancestor (the goal) is to be a parent (the condition). That definition is a little lacking, but with recursion, we can make it better.
ancestor(X, Y) :- parent(X, Y).
ancestor(X, Y) :- parent(X, Z), ancestor(Z, Y).By introducing the intermediate variable Z in the body, we have solved the problem of what is means to be an ancestor. Now we’re asserting that to be an ancestor means either that X is the parent of Y, but it also could mean that X is the parent of someone who has an ancestral relation to Y. That is logically what it means to be an ancestor.
In first-order logic we might write this as
ancestor(X, Y) ← parent(X, Y) ∨ (parent(X, Z) ∧ ancestor(Z, Y)).But how does this code actually execute? We haven’t actually implemented any code to say how we find the ancestor - we have only said what an ancestor is! The trick lies in how Prolog code is executed. In a functional language, the compiled machine code boils down to ‘calculate a bunch of things and return the result of those calculations’, and this is how the interpreter of that machine code works- by crunching numbers.
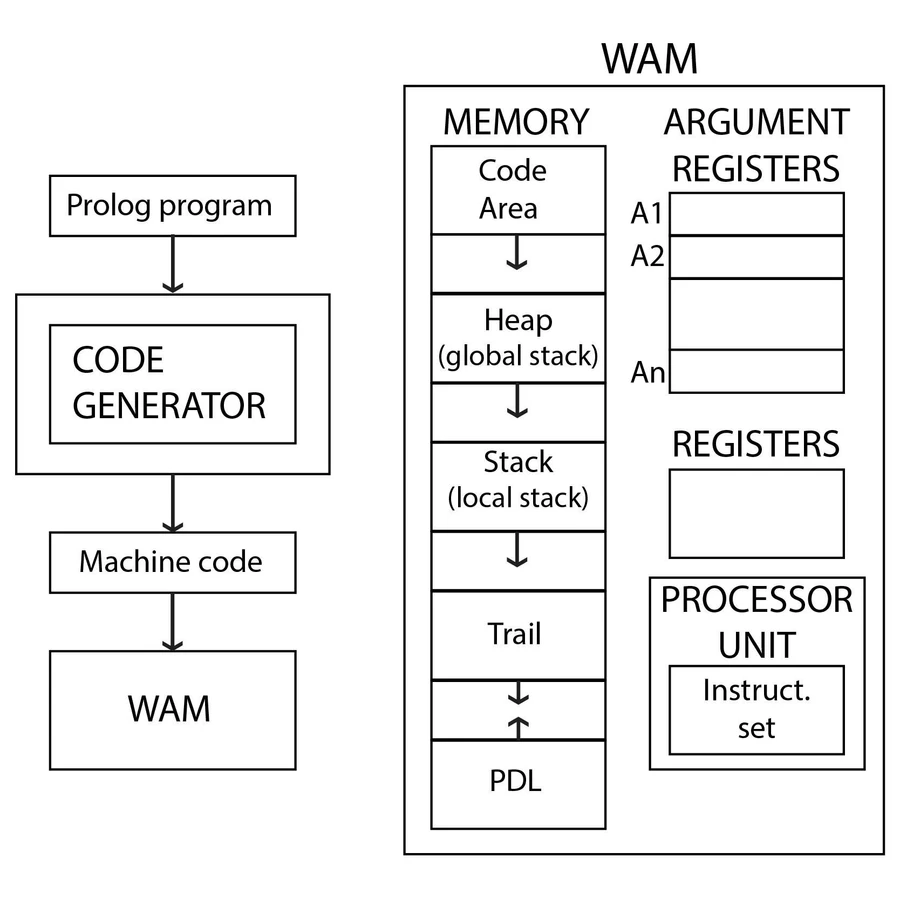
However in Prolog, and in logic languages, it’s fundamentally different. Prolog relies on the Warren Abstract Machine (WAM), the literature for which is highly dense and formal, but here is a simple explanation. The WAM is a stack-based abstract machine with several components:
- The current environment, implemented as a stack
- The heap, which stores terms.
- The trail, which keeps track of changes to variables (E.G., binding of X to John) for the purposes of backtracking and undoing changes
The core way in which the WAM derives the correct results from our clauses is via a depth-first ‘search’. When we define ‘ancestor’ the WAM stores information about ‘Ancestor’ in the heap, like the arity and the conditions.
When we call ‘ancestor’ with bound parameters, E.G., ancestor(John, Jill)., a lookup is performed for ancestor, after which X and Y are bound to John and Jill respectively. This is called unification, and is similar to pattern matching- if a pattern doesn’t match, the goal fails.
A lookup is performed on parent(John, Jill). If every condition in the body evaluates to true, then the predicate is true- goals are recursively evaluated. If the goal fails, the WAM will backtrack and try a different path to make the goal succeed. In this case John is the parent of Jill, so the answer is true.
The Prolog interpreter can also use ‘substitution’ to derive new facts. For example if we call ancestor(John, X). the interpreter is smart enough to retry executing the code with X instantiated as Jill and Jack- the goal is true if X is either of those two values. The values of X for which the expression is true are returned.
This allows the WAM to derive new facts for us. Peter Norvig builds a Prolog interpreter in Common Lisp that does this very thing in his book. For anyone wanting a deeper hands-on understanding, I’d highly recommend it- you should have everything you need to build a Prolog interpreter of your own. After writing a simple interpreter, you can enrich it with more interesting properties, and it’s possible to write some really fascinating meta-interpreters in Prolog itself with only a few lines of code.
I’ve always believed that the best way to improve at programming, especially when learning a new paradigm, is to solve puzzles- specifically recursive puzzles. I want to take some of our favourite functional constructs (map, filter, reduce) and explain how we might write these in Prolog.
Map
When looking at solving a problem in a logic language it is best to start by considering the goal. In a functional language, we might say that to map is to calculate a linear transform between one data structure and another. But in Prolog, I would ask what is a Mapping between two structures? And in what context?
A mathematician would look at two structures under a function and say that they are mapped if the two structures have the property of being bijective under a function. Bijectivity refers to the property that every element in the first structure has one-and-only-one corresponding element in the second structure.
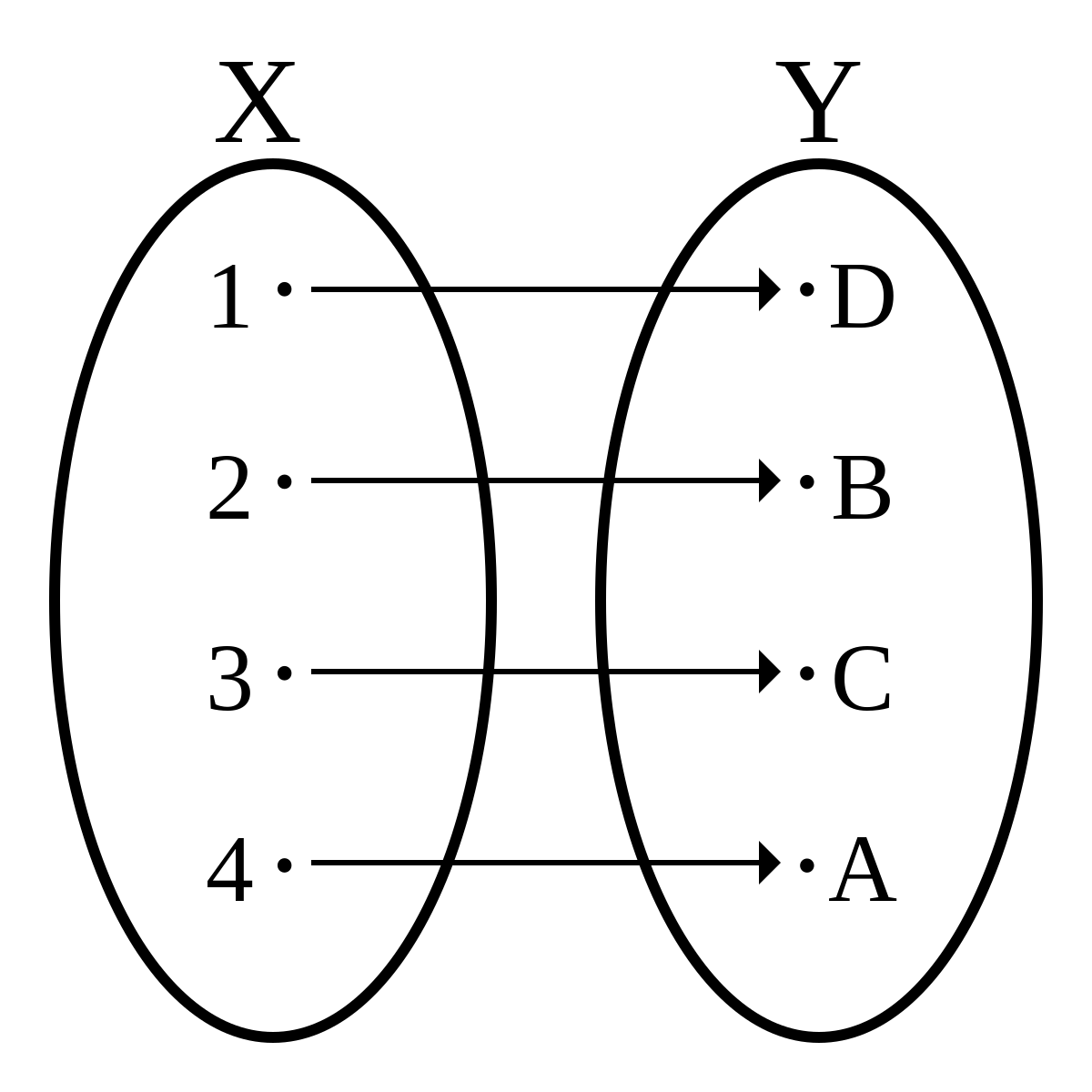
For every X in structure 1, and for every corresponding Y in structure 2, there is some relation between them. What is that relation? It is the mapping predicate. We should also consider our base case so that we have an endpoint. We can then derive Map to be
map(_, [], []).
map(P, [X|Xs], [Y|Ys]) :- call(P, X, Y), map(P, Xs, Ys).In our base case, we have used the underscore to denote that we don’t care what that value is- it can be any value. If the first list is empty, and the second list is empty, then that’s a mapping.
When the lists are not empty, the case is more interesting. Firstly, notice that we can use destructuring on the lists. Secondly, we use a built-in predicate called ‘Call’, which applies a predicate to some arguments- and then we recur. Eventually the lists will be empty, if the lists are bijective.
So this code says ‘Map is true when the lists are empty, or when the supplied predicate is true for every element between the two lists’.
Filter
Whereas maps are bijective due to the predicate being true for every corresponding element in List 1 and List 2, in filters that’s not the case. Sometimes, the predicate fails. We can deal with this by adding an extra clause.
filter(_, [], []).
filter(P, [X|Xs], [X|Ys]) :- call(P, X), filter(P, Xs, Ys).
filter(P, [X|Xs], Ys) :- not(call(P, X)), filter(P, Xs, Ys).filter is true if the two lists are empty, OR the filter is true if for every element in list 1 there is a corresponding element in list 2 which is the same and satisfies the given predicate P, OR that there is a filtration between the rest of List 1 and List 2.
Note that in the case of filter(Parent, X, [John]), X could be any list that contains John- whereas this function will return simply [John]. It (almost) never makes sense to call filter the inverse way- but it’s cool that we can try!
Reduce
Reduce brings us onto tail recursion. During a reduction in functional style, we call a function between an accumulator and each successive value until we build up the accumulator into our result.
We can do something similar in Prolog.
reduce(predicate, [], Result, Result).
reduce(predicate, [X|Xs], Acc, Result) :- call(predicate, Acc, X, Acc2), reduce(predicate, Xs, Acc2, Result).We define an intermediate value: the result when the predicate is true when called against X and the last intermediate value.
For every element in the list, if the predicate is true when provided with the arguments of the element, the last intermediate value, and the new intermediate value, and if there’s a reduction for the next element of the list, and the result does not change, then Reduce is true.
The base case states that the list must be empty and the accumulator should be equivalent to the final result (which is correct).
In my opinion this is the hardest example to grasp, due to the accumulator, and it’s notable that again this is uni-directional (we cannot find the inverse of the reduction). But by grasping this example, you are well on your way to becoming a whizz logician!
Conclusion
In ordinary programming paradigms we might ask ourselves ‘How do I explain to the machine what calculations it must perform in order to achieve my desired goal?’ In logic languages, it’s the inverse- we ask ‘How do I explain to the machine my goal as correctly as possible such that the facts I want can be derived?’ We can be a little more sure that our program is correct if it runs and returns a value because of the constraints.
I hope that in giving you this new perspective, you can apply it in your own abstractions. It can at least give you a deeper understanding about technologies you already use, like SQL and XT Datalog. More importantly, I believe logic programming’s greatest value is to help us realise how often we overestimate our own understanding of concepts we use on a daily basis.
If you’re interested in more, check out extensions to Prolog such as Mercury and Lambda Prolog!




