

Like many in the Clojure community, I’ve considered JSON as a rather horrible syntax (compared to the obvious superiority of EDN).
As a configuration format, JSON is used almost everywhere: npm’s package.json, AWS CloudFormation, Hashicorp Terraform, Open API, .NET, the list is endless.
For me, the worst issue is the exclusion of comments. Of all the problems we’re leaving to future generations, the complete lack of explanation in the configuration files of future legacy software systems must be among the most irksome. Understanding is good, clear explanations are good; discouraging the use of helpful and clarifying comments is inexcusable.
The situation would improve if developers stopped adopting JSON for configuration files - and there are JSON-like formats available that are much better suited to this task, such as Hjson, Jsonnet, YAML and others. The downside of these is that they require special format reading software which is rarely built-in to languages. At JUXT, we use Aero, which we consider to be the best of all worlds.
Change the perspective
Let’s start again and think about what JSON is:
{
"list": ["string" {"map": {"key": "value"}}]
}It’s maps, lists, maps-of-lists, lists-of-maps, lists-of-lists, maps-of-maps.
In fact, from a Clojure perspective, things couldn’t be better: Clojure is, hands down, the most adept language at processing this near-ubiquitous format. Of course, we’re a little bit biased at JUXT!
Back when everything was XML, and everyone wrote Java (or C#), I remember working on a large project. We spent weeks (literally, weeks!) working on serialization and de-serialization of data from XML into Java and back. I/O is a critical part of any program. Getting data in and out of a program shouldn’t be that hard, and with Clojure and JSON it isn’t.
+-----------------------------------+-----------------------------------+ | Data format | Ideal processing language | +-----------------------------------+-----------------------------------+ | CSV | SQL | +-----------------------------------+-----------------------------------+ | SGML | DSSSL | +-----------------------------------+-----------------------------------+ | XML | XSLT | +-----------------------------------+-----------------------------------+ | JSON | CLJ/S (Clojure) | +-----------------------------------+-----------------------------------+
It’s almost as if, behind the scenes, there’s been this Grand Lisp Conspiracy to get everyone programming in Lisp, whether or not they realize it.

By disguising itself with some ornamental punctuation, JSON has infected the whole world with Lisp.
JSON Schema
JSON Schema is an emerging standard which is used to define the structure of JSON documents. It’s mostly used to validate that JSON documents conform to expectations. However, since JSON allows anyone to define new keywords and add them to vocabularies, I believe JSON Schema should be thought of as a more general way of specifying meta-data.
When combined with meta-data, data takes on some magical super-powers.
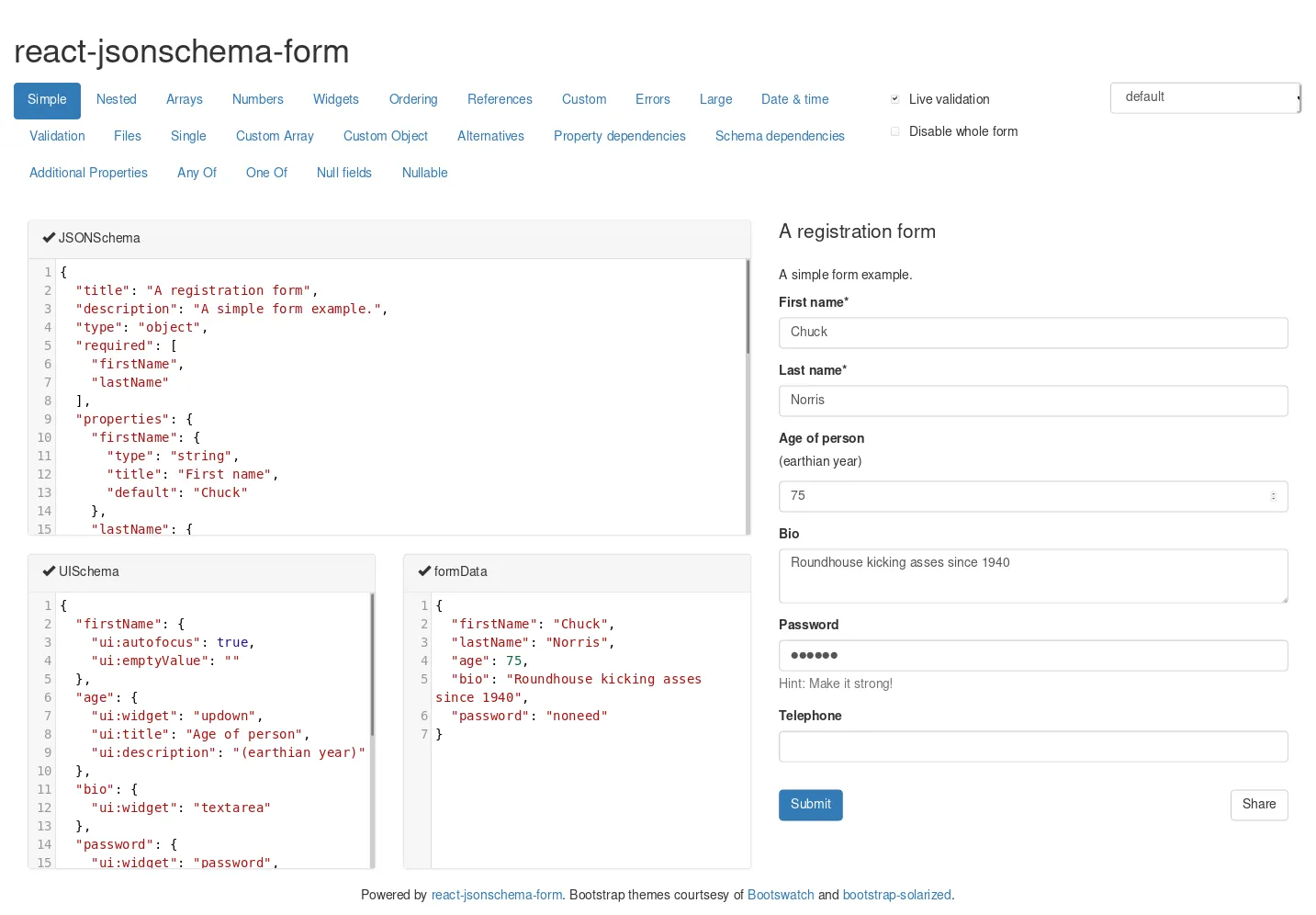
One example is Mozilla’s React JSON Schema Form which demonstrates a React component that can dynamically produce forms via introspecting JSON data and its schema.
I believe there will be plenty of other uses of JSON Schema in the future.
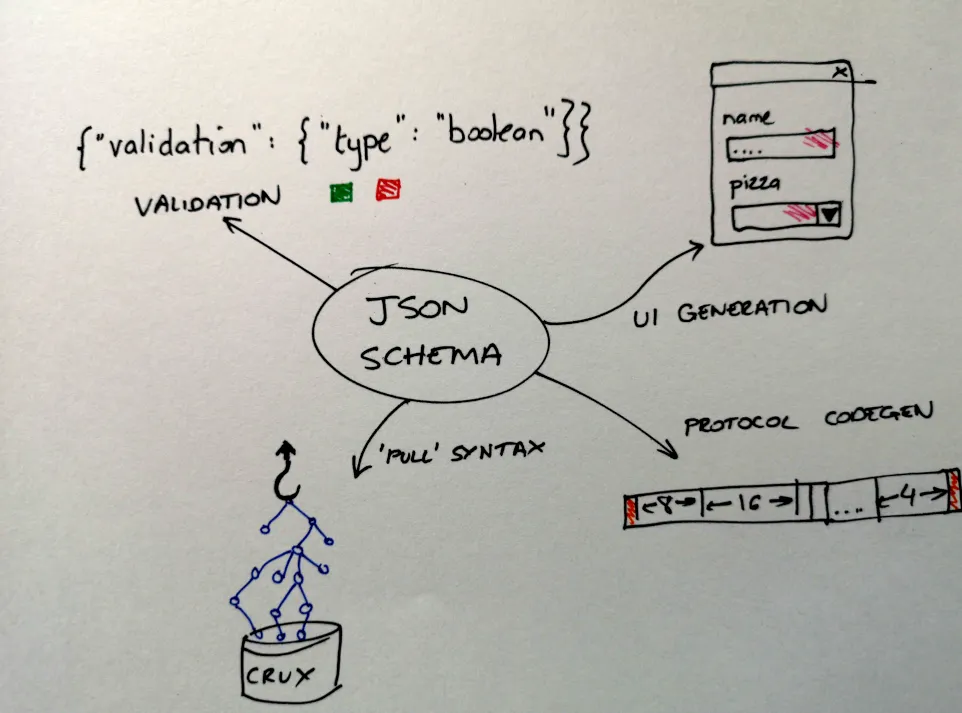
One example I’m particularly interested in is the use of JSON Schema as a pull-syntax for our Crux database. JSON Schema allows you to declare the structure of the document you want to pull out of Crux, Crux will perform the necessary graph queries against its documents. The result documents will successfully validate against the schema, as the query is the schema.
jinx
I wanted to explore the potential of JSON Schema to provide a way of accessing metadata about documents in order to make the data more useful and powerful.
Thanks to some help from some colleagues (in particular, Shivek Khurana and Sunita Kawane), these explorations have resulted in a new Clojure(Script) library called jinx, which provides schema-powered capabilities, which of course includes validation. We’re hoping this can be used for a variety of applications, not just to validate data documents but to access the annotations made via the JSON Schema document.
A quick example:
(juxt.jinx.validate/validate
{"firstName" "John"
"lastName" "Doe"
"age" 21}
(juxt.jinx.schema/schema
{"$id" "https://example.com/person.schema.json"
"$schema" "http://json-schema.org/draft-07/schema#"
"title" "Person"
"type" "object"
"properties"
{"firstName"
{"type" "string"
"description" "The person's first name."}
"lastName"
{"type" "string"
"description" "The person's last name."}
"age" {"description" "Age in years which must be equal to or greater than zero."
"type" "integer"
"minimum" 0}}}))
=>
{:instance {"firstName" "John", "lastName" "Doe", "age" 21},
:annotations
{"title" "Person",
:properties
{"firstName" {"description" "The person's first name."},
"lastName" {"description" "The person's last name."},
"age"
{"description"
"Age in years which must be equal to or greater than zero."}}},
:type "object",
:valid? true}Our jinx library is still in ALPHA status but it would be great to hear all feedback and comments. It’s available on GitHub at https://github.com/juxt/jinx.


