

I’ve recently been working on our distributed bitemporal indexing strategy in XTDB 2.x. I’ve been using the industry-standard TPC-H OLAP benchmark as my sample dataset - I’m pleased to say that the early indications are looking promising, more details to come soon!
This blog, though, is about a couple of hours of my life yesterday evening spent tracking down an out-of-memory (OOM) error on a throwaway script written in Clojure, in the vague hope it spares someone else a similar fate. 😅
Transforming data
TPC-H is a widely recognised database benchmark that includes both queries and data modifications. TPC publish a data generation tool used to populate a database and prepare it for the benchmarking process. For XTDB benchmarking, I wanted to take the Java objects generated by the tool and write them to a Transit file for easier handling in Clojure.
I was happily hacking away at my REPL, as us Clojure developers so frequently do - trying something, seeing what happened, trying something else, rinse, repeat - in a good flow.
At small scales, I naturally didn’t have any issues.
Finally, the small scale worked, and I turned my attention to larger scales. The next step was to run this script and generate the full benchmark data set.
Turning it up to 11
The full generation process involves transforming around 8 million Java objects for writing into my Transit file.
At this point, I run the first stage of the pipeline - just a simple transformation of Java objects from the TPC-H generator into a Transit file. However, I give it 30 seconds, and my JVM slows down to a crawl - with its garbage collector (GC) doing a good job of further warming up my study. 1
It’s a relatively small transformation, so my first check is whether I’m ‘holding on to the head’ of any lazy sequences. Nothing obvious, so I head to a profiler to see what’s going on - the old-gen (orange) was filling up, not able to be garbage collected:
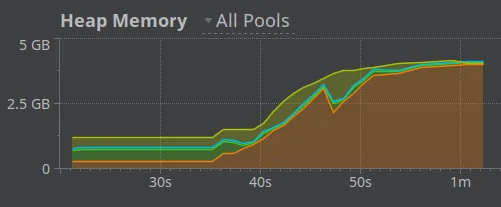
Having a look at the objects in the memory snapshot, I see a rather large clojure.lang.TransformerIterator object, containing a LinkedList with ~3M not-small elements.
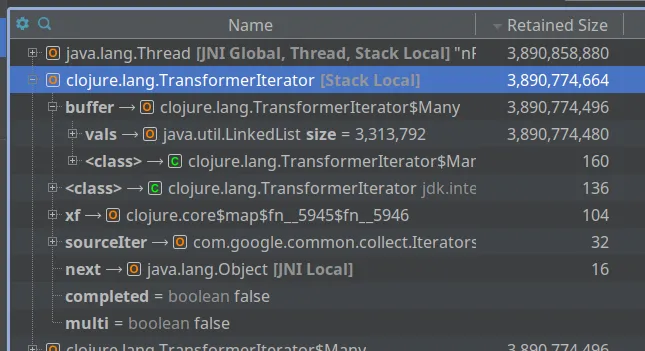
Yikes.
This isn’t a class I’ve seen before in clojure.lang - turns out it’s created in the clojure.core/sequence function, when you supply a transducer - this function essentially transforms between a transducer-style operation to a more traditional lazy-sequence. 2
In my case, I narrowed it down to a call to (sequence (mapcat f) coll).
I’d confirmed f returned a lazy sequence, and mapcat and sequence are both (in theory) lazy - but the issue came from the combination of the two.
Diving into the source code
The ‘step’ function of the mapcat transducer is roughly implemented as follows: 3
(defn mapcat [f]
(fn [rf]
(fn [result el]
(reduce rf result (f el)))))That is, for each individual element of the input sequence, we pass each element of the result of (f el) to the upstream reducer (rf) for processing.
sequence, on the other hand, quickly delegates to clojure.lang.TransformerIterator, an internal implementation class of the Clojure standard library.
It stores the transducer and the input collection as fields on the object.
As its name suggests, this is an implementation of a Java iterator, so it needs to implement the usual hasNext() and next() methods.
However, to do this, as part of knowing whether there are more elements or not, it has to pull at least one element of the input collection, and apply the transducer.
When the transducer is mapcat, calling (f el) yields multiple elements, so the TransformerIterator has to buffer them to return one-at-a-time to its caller - and here’s where the problem lies!
We can think of the combination of sequence and mapcat behaving something like this:
;; pseudo-code
(defn sequence-mapcat [f, ^Iterator inner-iterator]
(let [buffer (LinkedList.)]
(reify Iterator
(hasNext [_]
(cond
(not (empty? buffer)) true
(.hasNext inner-iterator) (do
(doseq [el (f (.next inner-iterator))]
(.add buffer el))
(recur))
:else false))
(next [_]
(.pollFirst buffer)))))My f, though, was particularly expansive - one row in the input collection turning into (in one case) 6 million entries in the output - all of which were being added to that buffer. No wonder I got the OOM!
To demonstrate the difference, consider the following:
(let [f (fn [_]
(range))
coll [1 2 3]]
;; this hangs indefinitely, because `sequence` + `mapcat` essentially evaluates
;; `(first (doall (f 1)))` == `(first (doall (range)))`
#_(first (sequence (mapcat f) coll))
;; this essentially evaluates `(first (f 1))`, i.e. `(first (range))`, which returns `0`
(first (mapcat f coll)))… whereas I (naively, in hindsight) assumed (sequence (mapcat f) coll) always behaved the same as (mapcat f coll)!
Alex Miller explained it very succinctly:
Sequences are inherently a “pull” model and transducers are a “push” model.
sequenceis a pull API over the push model and, when you push something big in the intermediate step, well … it has to go somewhere.
Going fully lazy
I did try going fully lazy at that point, but I ran into (I think) exactly the same issue as Alessandra Sierra documents in ‘Clojure Don’ts: Concat’. For me, this manifested itself as another OOM - this time, a deep stack of cons cells:
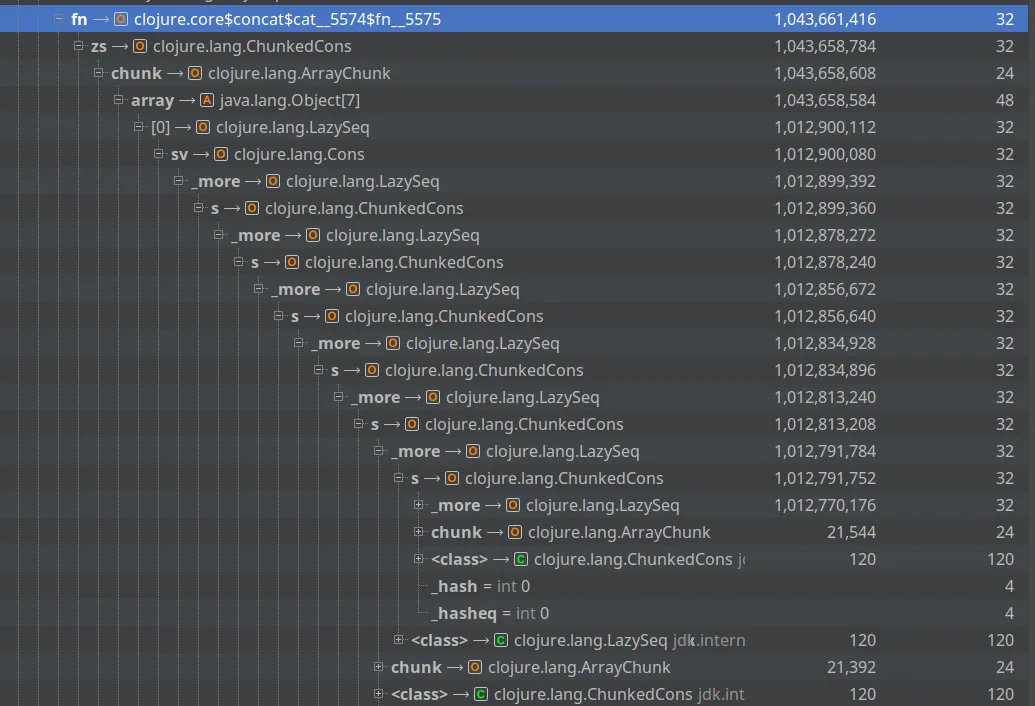
Admittedly I didn’t pursue this avenue for long - it was getting late!
Going full transducer
So, instead, I went all the way the other way - I went ‘full transducer’.
I used transduce with a side-effecting ‘reducer’ to stream each element out to the output file:
;; pseudo-code
(with-open [os (io/output-stream ...)]
(->> input-coll
(transduce
(comp (mapcat f)
(map-indexed (fn [idx el]
...))
...)
(completing
(fn
([] nil)
([_ el] (write! os el)))))))At which point, my memory graph looked like the traditional sawtooth shape that JVM dreams are made of:
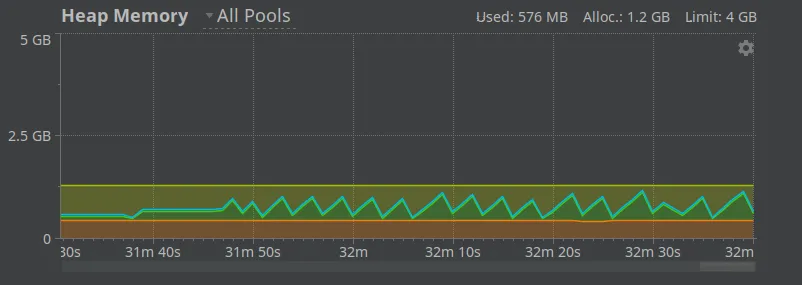
… and I could rest easy once more 😊


