

Crux is now XTDB September 2021 Update: Crux has recently been renamed XTDB. The official home for XTDB is now https://xtdb.com.
We have just released Crux - an open-source bitemporal database.
What is Crux?
Crux is a document store that indexes documents for graph query. The
indexes are bitemporal, meaning that you can query against valid time
and transaction time, the usefulness of which is covered in our
previous post “the value of
bitemporality”.
Unbundled
Crux is an unbundled database - to use Martin Kleppman’s phrase - shipping as a connected set of pluggable parts. This means that users can swap out parts and contribute their own, and that Crux itself follows the Unix philosophy of each part doing one thing particularly well.
This pluggability allows Crux to scale with you as your scaling needs increase. You can start out using Crux with the transaction log being a local-disk based implementation, and then in future you could switch it out to Kafka, which offers much higher data throughput and retention guarantees.
With the open, unbundled architecture, it’s intended that Crux be extended and experimented with. The various parts in Crux are described by Clojure protocols, meaning that users can get in and provide their own implementations that would either fully replace or decorate the existing ones.
How Crux Works
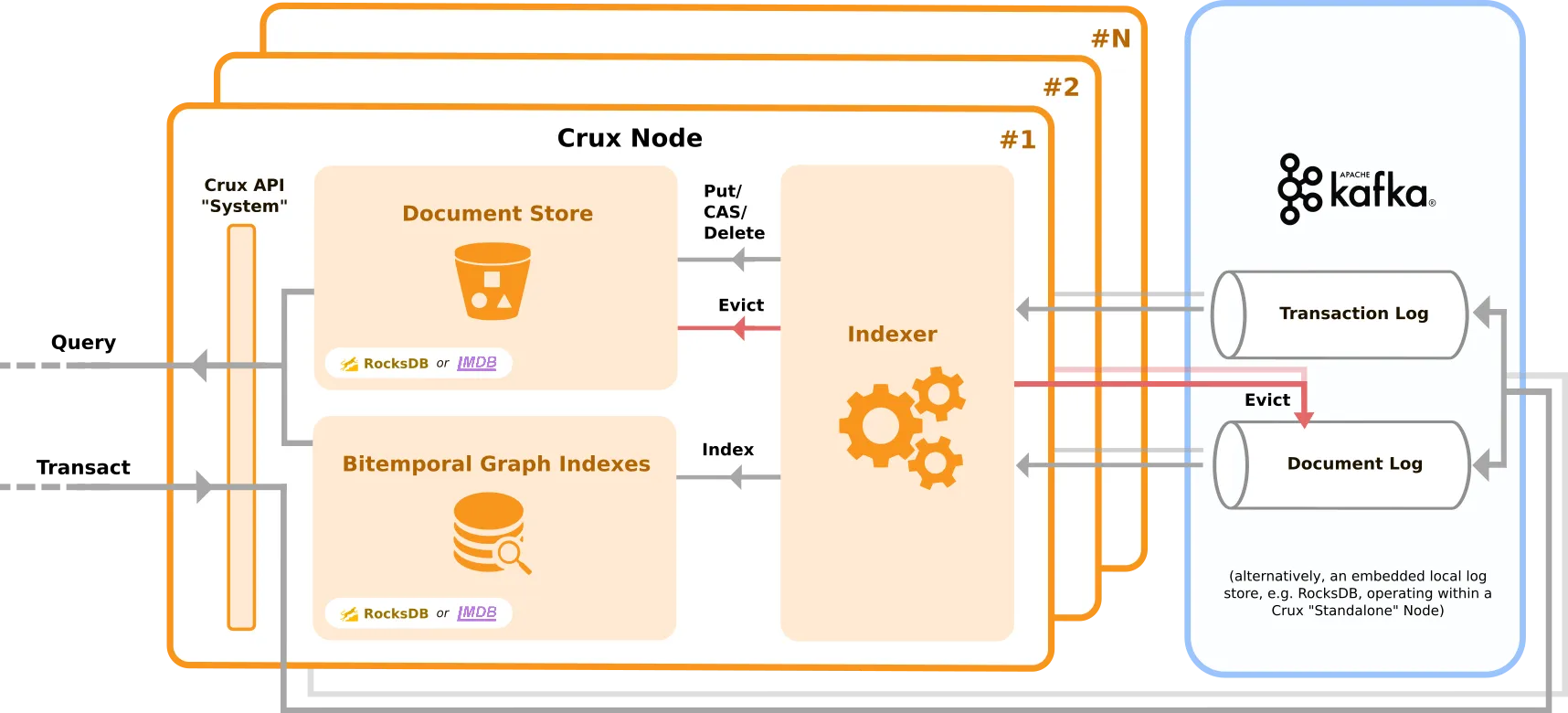
Crux is schemaless, with transactions being submitted through the Crux API. The data is then sent to two event-log topics for storage: the transaction topic and the document topic.
We use two topics because whilst the transaction topic is immutable, messages in the document topic can be permanently erased, forming the basis of Crux’s ground-up strategy to provide ease of content eviction for data privacy reasons, to align with compliance regimes such as GDPR.
Using a separate topic for the content documents also allows for compaction to remove duplicates, as the message ID is a content hash of the document. From a Kafka perspective, the transaction topic uses a single Kafka partition, but it is in our roadmap to shard the document topic to potentially use multiple partitions.
The event-log that Crux uses is the golden store of data, with Crux leveraging Kafka’s infinite retention capability.
Crux Nodes will then ingest the data from the event-log and index the transactions and documents locally into a local Key/Value store such as RocksDB or LMDB, which acts as the foundation for both a local document store and a set of bitemporal indexes that Crux maintains for graph query. RocksDB and LMDB use fundamentally different data structures and therefore present a choice of performance characteristics and trade-offs.
Crux currently supports both a Java and Clojure API. See the JavaDocs.
Transacting and Querying
Crux supports an Edn Datalog format, similar to - though not the same as - Datomic’s. To get a feel of transacting to and querying against Crux, check out the query documentation and/or read Ivan Fedorov’s “a bitemporal tale”.
Crux supports four transaction operations:
-
PUT -
DELETE -
CAS -
EVICT
PUT will store a document whereas DELETE will delete it from a given
valid time, but the data will still be stored in Crux history. Use
EVICT to get rid of data permanently, either for all of history, or
for a given valid time window. Use CAS to compare-and-swap, to
ensure that the data in a document/entity is what you think it is before
adding a new version, or else abort the transaction.
Inside of Crux we use a Worse Case Optimal Join algorithm, which enables the query engine to lazily stream out results for an arbitrary complex query with multiple join conditions and clauses. This, in combination with an external merge sort used for additional sorting, means that we avoid manifesting intermediary results in memory.
Deployment
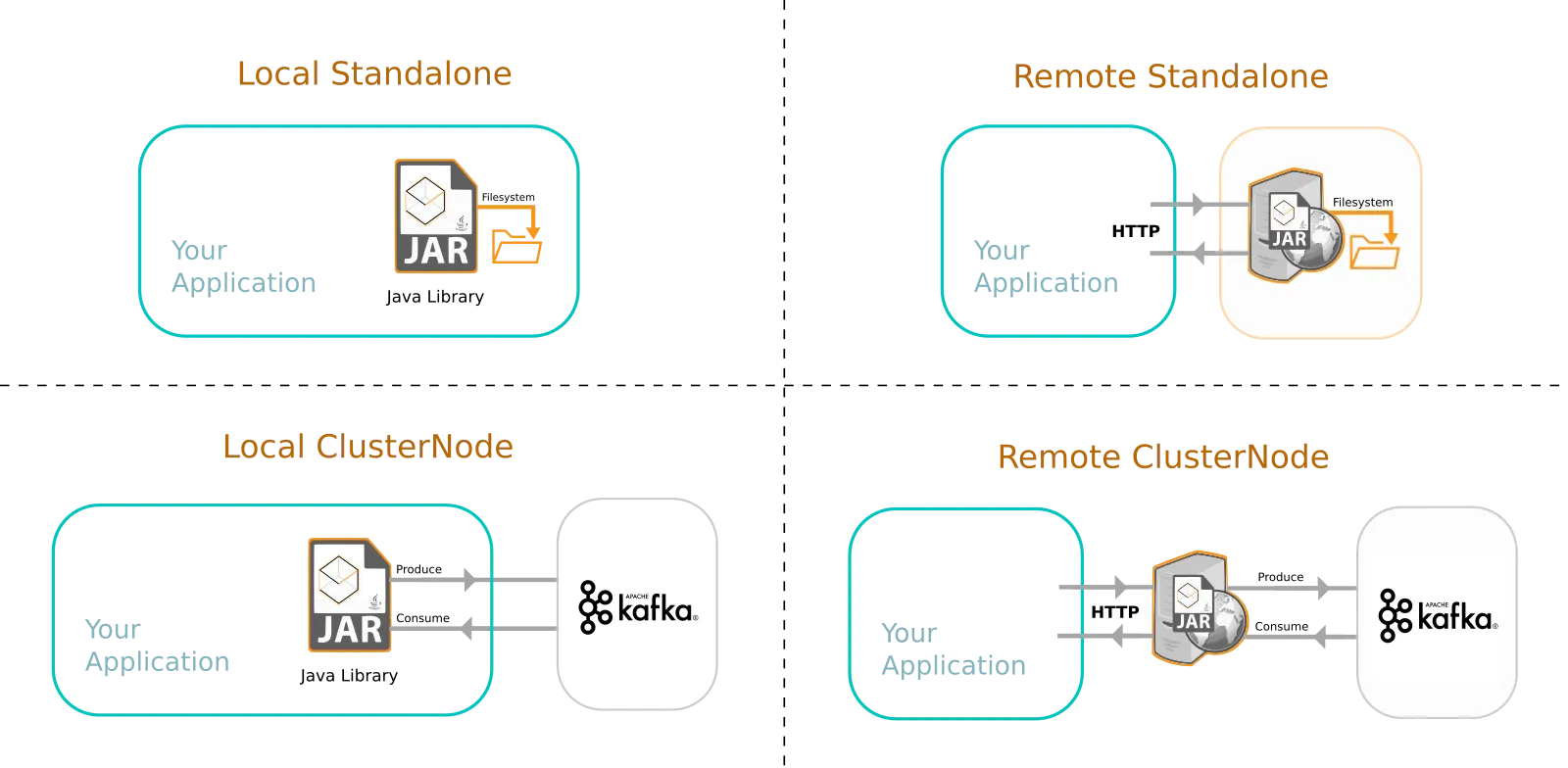
Crux can be deployed as a JAR file within your application, or Crux has a HTTP server that you can use. You can use Crux in a standalone mode without Kafka (substituting in a local disk-based event-log), or you can deploy a cluster of Crux nodes that use Kafka.
Open
Crux is open source so that you can see the code, commit history, warts and all. You can see the GitHub issues where design decisions are made, and you can contribute in this process. You can fork Crux and send PRs our way. We encourage developers to try out Crux and to expose and publish patterns of using it, to feedback their ideas and critique.
Crux is a product that JUXT will offer various support models for, including enterprise support and managed hosting. If you have any questions about Crux or would like to talk to us about using it, please email us or visit our Zulip.
Have a play with XTDB - add the JAR to your project and scale up from there. Crux is Alpha. Please raise any issues on our GitHub.
%20--%3e%3csvg%20version='1.1'%20id='Layer_1'%20xmlns='http://www.w3.org/2000/svg'%20xmlns:xlink='http://www.w3.org/1999/xlink'%20x='0px'%20y='0px'%20viewBox='0%200%20184.25%20188.88'%20style='enable-background:new%200%200%20184.25%20188.88;'%20xml:space='preserve'%3e%3cstyle%20type='text/css'%3e%20.st0{fill:%23C9C9C9;stroke:%23C9C9C9;stroke-miterlimit:10;}%20.st1{fill:%23C9C9C9;}%20.st2{fill:%23F8961D;}%20%3c/style%3e%3cg%3e%3cpath%20d='M36.22,160.03l-1.47,1.13c-0.81-1.06-1.79-1.86-2.93-2.41c-1.14-0.55-2.39-0.82-3.75-0.82c-1.49,0-2.87,0.36-4.14,1.07%20c-1.27,0.72-2.26,1.68-2.96,2.88c-0.7,1.21-1.05,2.56-1.05,4.07c0,2.28,0.78,4.18,2.34,5.71c1.56,1.52,3.53,2.29,5.91,2.29%20c2.62,0,4.81-1.03,6.57-3.08l1.47,1.12c-0.93,1.19-2.09,2.1-3.49,2.75c-1.39,0.65-2.95,0.97-4.67,0.97c-3.27,0-5.85-1.09-7.74-3.26%20c-1.58-1.84-2.38-4.06-2.38-6.66c0-2.74,0.96-5.04,2.88-6.91c1.92-1.87,4.32-2.8,7.21-2.8c1.75,0,3.32,0.35,4.73,1.04%20C34.17,157.81,35.32,158.78,36.22,160.03z'/%3e%3cpath%20d='M66.09,156.56h3.72c2.08,0,3.48,0.08,4.22,0.25c1.11,0.25,2.01,0.8,2.71,1.63c0.7,0.84,1.04,1.86,1.04,3.08%20c0,1.02-0.24,1.91-0.72,2.68c-0.48,0.77-1.16,1.36-2.05,1.75c-0.89,0.39-2.12,0.6-3.68,0.6l6.72,8.68h-2.31l-6.72-8.68h-1.06v8.68%20h-1.87V156.56z%20M67.96,158.39v6.35l3.22,0.03c1.25,0,2.17-0.12,2.77-0.36c0.6-0.24,1.07-0.62,1.4-1.14c0.33-0.52,0.5-1.1,0.5-1.75%20c0-0.63-0.17-1.2-0.51-1.71c-0.34-0.51-0.78-0.88-1.34-1.1c-0.55-0.22-1.47-0.33-2.75-0.33H67.96z'/%3e%3cpath%20d='M107.87,156.56h1.87v11.28c0,1.34,0.03,2.17,0.08,2.5c0.09,0.74,0.31,1.35,0.65,1.85c0.34,0.5,0.86,0.91,1.56,1.25%20s1.41,0.5,2.12,0.5c0.62,0,1.21-0.13,1.78-0.39c0.57-0.26,1.04-0.63,1.42-1.09c0.38-0.47,0.66-1.03,0.84-1.69%20c0.13-0.47,0.19-1.45,0.19-2.92v-11.28h1.87v11.28c0,1.67-0.16,3.02-0.49,4.05c-0.33,1.03-0.98,1.92-1.96,2.69%20c-0.98,0.76-2.16,1.14-3.55,1.14c-1.51,0-2.8-0.36-3.88-1.08c-1.08-0.72-1.8-1.67-2.16-2.86c-0.23-0.73-0.34-2.04-0.34-3.94V156.56%20z'/%3e%3cpath%20d='M149.88,156.56h2.18l4.47,7.27l4.5-7.27h2.16l-5.57,9.03l5.94,9.66h-2.18l-4.85-7.89l-4.87,7.89h-2.19l5.97-9.65%20L149.88,156.56z'/%3e%3c/g%3e%3cg%3e%3cline%20class='st0'%20x1='90.86'%20y1='62.68'%20x2='90.56'%20y2='10.99'/%3e%3cpolygon%20class='st1'%20points='90.86,61.76%2091.08,61.92%20139.14,97.04%20138.34,97.39%2090.86,62.68%2042.8,97.39%2042.36,96.78%20'/%3e%3cpolygon%20points='90.78,10.69%2090.56,10.53%2042.31,45.8%2043.13,47.05%2090.56,12.38%20138.09,46.71%20138.09,96.48%2090.56,130.81%2043.19,96.18%2041.91,97.1%2090.12,132.34%2090.56,132.66%20139.59,97.25%20139.59,45.94%20'/%3e%3cpolygon%20points='90.57,81.07%2090.56,81.07%2042.31,45.8%2042.31,47.66%2090.12,82.61%2090.56,82.93%2090.57,82.92%20'/%3e%3cg%3e%3cline%20class='st2'%20x1='90.57'%20y1='82.93'%20x2='90.57'%20y2='82.93'/%3e%3cpolygon%20class='st2'%20points='90.57,81.07%2090.57,81.07%2090.58,81.07%2090.58,82.92%20139.6,47.52%20139.6,45.94%20'/%3e%3c/g%3e%3c/g%3e%3c/svg%3e)


