

A great deal can be achieved in the first few years of a software project, with a small team and the right tools we can quickly deliver features to appease both businesses and their clients. In the early stages of a project, delivery is often prioritized over architecture, but the architecture needs to evolve if the software is to be developed and maintained in the longer term. Any project that lives for longer than a few years will experience change, business requirements will change, developers will come and go, platform services on which the software depends will be deprecated and replaced, deployment environments will change, and new technologies will offer new possibilities as older technologies become obsolete.
Abstraction is at the heart of software architecture, separating what
from how enables us to focus on the core business problem we are
trying to solve without getting lost in the details of a particular
implementation.
Abstraction
Depend on abstractions, not on concretions
— Dependency Inversion Principle
Concretion is when we depend on implementations as opposed to abstractions, consider the following application that exposes a REST API to retrieve a blog article from a SQL database:
(ns app.db
(:require [next.jdbc.sql :as sql]))
(defn get-article-by-id
"`data-source`: javax.sql.DataSource, `id`: article id"
[data-source id]
(sql/get-by-id data-source :article id))(ns app.server
(:require [app.db :as db]
[reitit.ring :as ring]))
(defn get-article [data-source request]
(let [id (get-in request [:path-params :id])
article (db/get-article-by-id data-source id)]
{:status 200
:body article}))
(defn router [data-source]
(ring/router
[["/api/article/:id" {:get {:parameters {:path {:id int?}}}
:handler #(get-article data-source %)}]]))(ns app.system
(:require [app.server :as server]
[next.jdbc :as jdbc]))
(defn init [db-spec]
(let [data-source (jdbc/get-datasource db-spec) ;; javax.sql.DataSource
router (server/router data-source)] ;; reitit.core/Router
...))In the example, get-article is coupled to the implementation
get-article-by-id; the router is coupled to get-article. The result
is a rippling effect that requires the router and the handler to be
aware of the data-source yet the only function that needs to know
about the data-source is get-article-by-id. We need a running SQL
database to test the current routing implementation.
We can invert the dependencies using abstraction. If we use the same
signature as db/get-article-by-id but remove the data-source we are
left with a function that takes an id and returns an article:
(fn get-article-by-id [id]
article)We can construct an implementation of our abstraction using higher-order functions:
(fn [id]
(db/get-article-by-id data-source id))
(partial db/get-article-by-id data-source)
#(db/get-article-by-id data-source %)We can now pass a function to server/get-article where we previously
passed the data-source, resulting in a pure function:
(defn get-article
"`get-article-by-id`: (fn [id] article)"
[get-article-by-id request]
(let [id (get-in request [:path-params :id])
article (get-article-by-id id)]
{:status 200
:body article}))Following the same approach, we can remove the first parameter of
get-article to form our next abstraction; a request handler:
(fn handler [request]
response)
#(server/get-article get-article-by-id %)The last change required is to the router; we need a way to pass in the
handler. Our example shows a single route, but in practice, we are
likely to have many; we can use a function that takes a route key and
returns a handler:
(fn route->handler [route]
(fn handler [request]
response))We can implement route->handler using a map:
{:get-article #(server/get-article get-article-by-id %)}We have now decoupled the router and handler, and removed the
data-source dependency:
(ns app.server
(:require [reitit.ring :as ring]))
(defn get-article
"`get-article-by-id`: (fn [id] article)"
[get-article-by-id request]
(let [id (get-in request [:path-params :id])
article (get-article-by-id id)]
{:status 200
:body article}))
(defn router
"`route->handler`: (fn [route] (fn [request] response))"
[route->handler]
(ring/router [["/api/article/:id" {:get {:parameters {:path {:id int?}}}
:handler (route->handler :get-article)}]]))At first glance, it may seem like a small change, but the refactored version is significantly different: the functions are now pure and can be tested in isolation without a running database.
We can
substitute
get-article-by-id for any function with the same signature without any
change to the app.server code. This could be a stub/mock during
testing, a wrapper that adds monitoring/logging/caching, or an
alternative implementation that fetches the article from a different
database or external source.
The router has a single responsibility: routing an incoming request to a handler. The handler also has a single responsibility: transforming the incoming request into an internal call where the action is performed.
Protocols
The protocol is another form of abstraction we can use to decouple modules, the approach is more object-oriented than functional, but protocols can be useful where we desire a more formal abstraction, or where it makes sense to form a cohesive collection of behaviors. In the previous example, we used a single function for the abstraction to retrieve an article, alternatively, we could use the Repository Pattern popularised by Domain Driven Design:
(ns app.article-repository)
(defprotocol ArticleRepository
(create [_ article])
(get-by-id [_ id])
(publish [_ id])
(archive [_ id])
(update-title [_ id title]))(ns app.db
(:require [app.article-repository :refer [ArticleRepository]]
[next.jdbc.sql :as sql]))
(defrecord SqlArticleRepository [data-source]
ArticleRepository
(get-by-id [_ id]
(sql/get-by-id data-source :article id))
...)(ns app.server
(:require [reitit.ring :as ring]
[app.article-repository :as article-repository]))
(defn get-article [article-repository request]
(let [id (get-in request [:path-params :id])
article (article-repository/get-by-id article-repository id)]
{:status 200
:body article}))The interface in this example is more formal in that we require the
repository namespace and refer to it directly, this is different from
the initial use of referring to the function defined via defn as we
refer to the abstraction, not the concretion of the protocol defined in
app.db.
It is more verbose, but it may be preferable to pass around instances of
protocols than to pass around lots of functions, particularly where many
behaviors are needed that are closely related; ultimately, it comes
down to a matter of style. One of the advantages of protocols over
functions is that it is clearer to the reader what a function depends
on; we require the namespace and our code points to where the protocol
is defined. On the other hand, this is not as flexible or as concise as
the functional alternative.
Composition
We achieved decoupling by introducing abstractions, the next step is to
compose our functions into a system. We start by creating a
data-source and using an anonymous function to wrap
db/get-article-by-id resulting in a function (fn [id] article). The
get-article-handler is created in the same way, resulting in a
function (fn [request] response) which is placed inside a map to
construct the route->handler abstraction:
(ns app.system
(:require [app.db :as db]
[app.server :as server]
[next.jdbc :as jdbc]))
(defn init [db-spec]
(let [data-source (jdbc/get-datasource db-spec) ;; javax.sql.DataSource
get-article-by-id #(db/get-article-by-id data-source %) ;; (fn [id] article)
get-article-handler #(server/get-article get-article-by-id %) ;; (fn [request] response)
route->handler {:get-article get-article-handler} ;; (fn [route] (fn [request] response))
router (server/router route->handler)] ;; reitit.core/Router
...))One of the trade-offs with this approach is that it results in
additional wiring; functions must be passed their dependencies and wired
together to form a system. The indirection means we can no longer jump
to the definition of get-article-by-id in the server namespace.
Whether the trade-offs are worth it is for you to decide; the
abstraction may be premature for short-lived projects, but decoupling
can help ensure larger projects are easier to maintain.
Composing large systems can be challenging. Processes need to be started and stopped in a particular order and the graph of dependencies can be large when following the Dependency Inversion Principle. We often reach out to frameworks such as Component or Integrant to help us construct larger systems, at the time of writing Integrant is the recommended option on our Clojure Radar.
The code to construct a system with Integrant is similar to the code we
defined in the let binding:
(defmethod ig/init-key ::get-article-by-id [_ {:keys [data-source]}]
#(db/get-article-by-id data-source %))
(defmethod ig/init-key ::get-article-handler [_ {:keys [get-article-by-id]}]
#(server/get-article get-article-by-id %))
(defmethod ig/init-key ::router [_ {:keys [route->handler]}]
(server/router route->handler))With the system declared in a map:
{::data-source {:db-spec db-spec}
::get-article-by-id {:data-source (ig/ref ::data-source)}
::get-article-handler {:get-article-by-id (ig/ref ::get-article-by-id)}
::router {:route->handler {:get-article (ig/ref ::get-article-handler)}}}As the system grows, we can split it up into cohesive modules, with maps created per module, then merged to form larger systems. We can make use of ig/pre-init-spec to assert the dependencies are as expected:
(s/def ::data-source #(instance? javax.sql.DataSource %))
(defmethod ig/pre-init-spec ::get-article-by-id [_]
(s/keys :req-un [::data-source]))Protocols work well here; we can validate them using satisfies? and catch wiring issues as the system is initialised:
(s/def ::article-repository #(satisfies? ArticleRepository %))
(defmethod ig/pre-init-spec ::get-article-handler [_]
(s/keys ::req-un [::article-repository]))
(defmethod ig/init-key ::get-article-handler [_ {:keys [article-repository]}]
#(server/get-article article-repository %))Frameworks such as Component or Integrant can help us when building larger systems, but we should take care to keep them at the periphery, design decisions taken by frameworks can have an impact on the design within your project. If you find yourself forced into using a certain data structure within your internal code to meet the restrictions of a framework you should consider whether it is helping or hindering your architecture.
Stability
Depend in the direction of stability
— Stable Dependencies Principle
Every system has stable and volatile components. In Clojure, we can consider a function to be stable if it is referentially transparent, conversely, we can consider any function which talks to the outside world or depends on something not referentially transparent as being volatile.
In our example application, the database is a volatile component which in turn makes the server and system namespaces unstable. The red arrows on the diagram show the components that are volatile due to their dependencies:
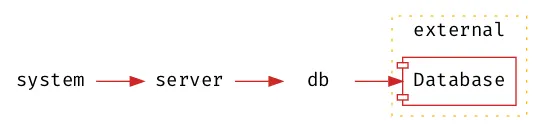
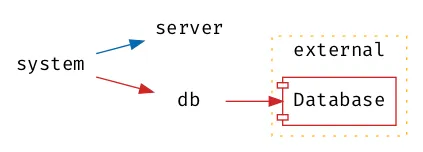
With the abstractions introduced, the server namespace no longer
depends on the volatile dependency; it is now a stable component.
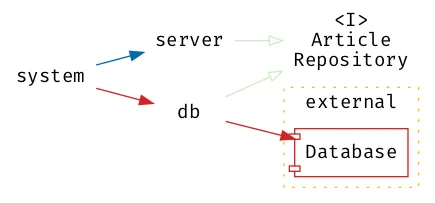
The alternate implementation with the ArticleRepository protocol has
additional arrows shown in light green that point to the protocol:
Example: Project Management Application
With such a trivial example the benefits of decoupling are perhaps not so obvious, consider a more complicated example of a project management application where users can create projects and manage tickets within a project, with notifications sent when the ticket status changes:
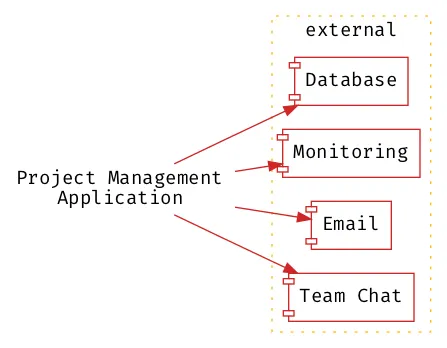
The managed services are volatile components, and implementations are required directly throughout the project, resulting in a tightly coupled system where everything is volatile. Whilst some components within a system must be volatile it is not desirable for everything to be volatile.
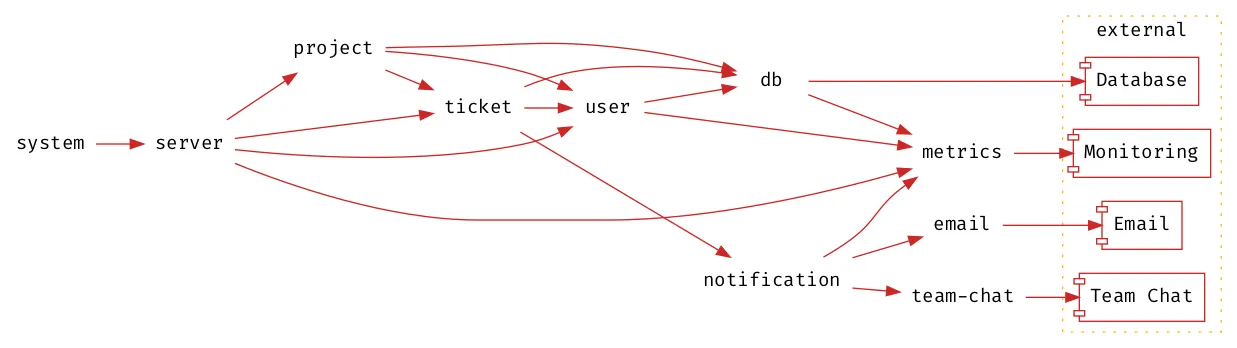
Layered Architectures
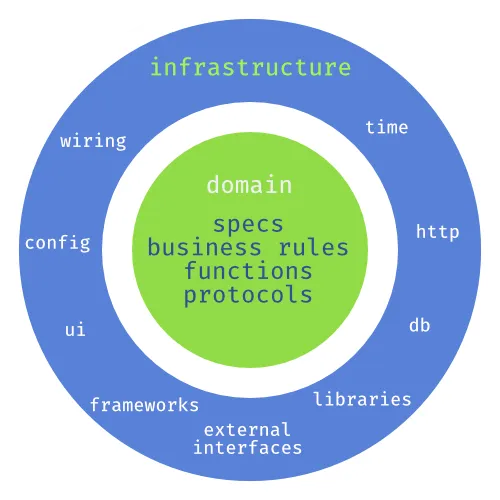
The Hexagonal Architecture, Onion Architecture, Clean Architecture, and Functional Core, Imperative Shell all put high-level business logic at the core of the application and make use of layers to keep low-level details such as the database and transport protocols at the periphery.
We can split the project management application into layers, separating
the core domain from the implementation specifics. The result is a
domain layer that depends only on abstractions and has no knowledge of
external dependencies; notice that the arrows never point from the
domain to the infrastructure layer. Abstractions are implemented in the
infrastructure layer and wired together to form a system:
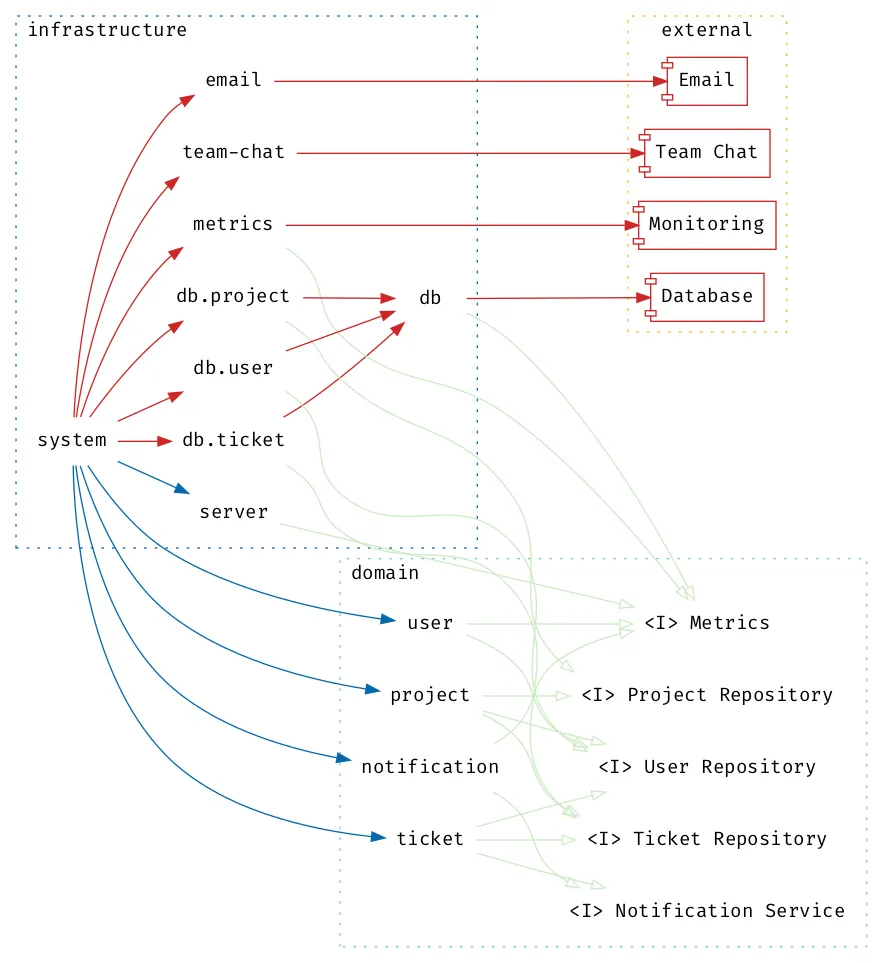
There are more nodes on the layered architecture and more edges where abstractions have been introduced, but the graph is not as deep and all components in the domain are now stable. The volatile components in the infrastructure provide implementations for the abstractions in the domain layer, the relationships within the domain layer remain the same but are now provided via abstractions.
Conclusion
Recognize that when you simplify things, you often end up with more things. Simplicity is not about counting. I’d rather have more things hanging nice, straight down, not twisted together, than just a couple of things tied in a knot. And the beautiful thing about making them separate is you’ll have a lot more ability to change it, which is where I think the benefits lie.
— Rich Hickey Simple Made Easy
Strictly separating what from how is the key to making how somebody else’s problem. If you’ve done this really well, you can pawn off the work of how on somebody else. You can say database engine, you figure out how to do this thing or, logic engine, you figure out how to search for this. I don’t need to know.
— Rich Hickey Simple Made Easy
Abstractions are fundamental if we strive to design larger systems that
are simple and maintainable in the long term. Look at your own codebase
and see where you’re tied to a certain implementation, draw a graph and
see where all the arrows point, find the volatile components and
consider introducing abstractions to decouple modules and to separate
what from how.
Software design is a well researched and understood problem, patterns and principles have been widely adopted since the start of the century, with many of the ideas the solutions are based on coming decades before that. Many of the ideas are equally applicable to functional programming and they can help us design applications that are maintainable in the longer term.
Image credit: jackrusher Generative art crafted in Clojure!




